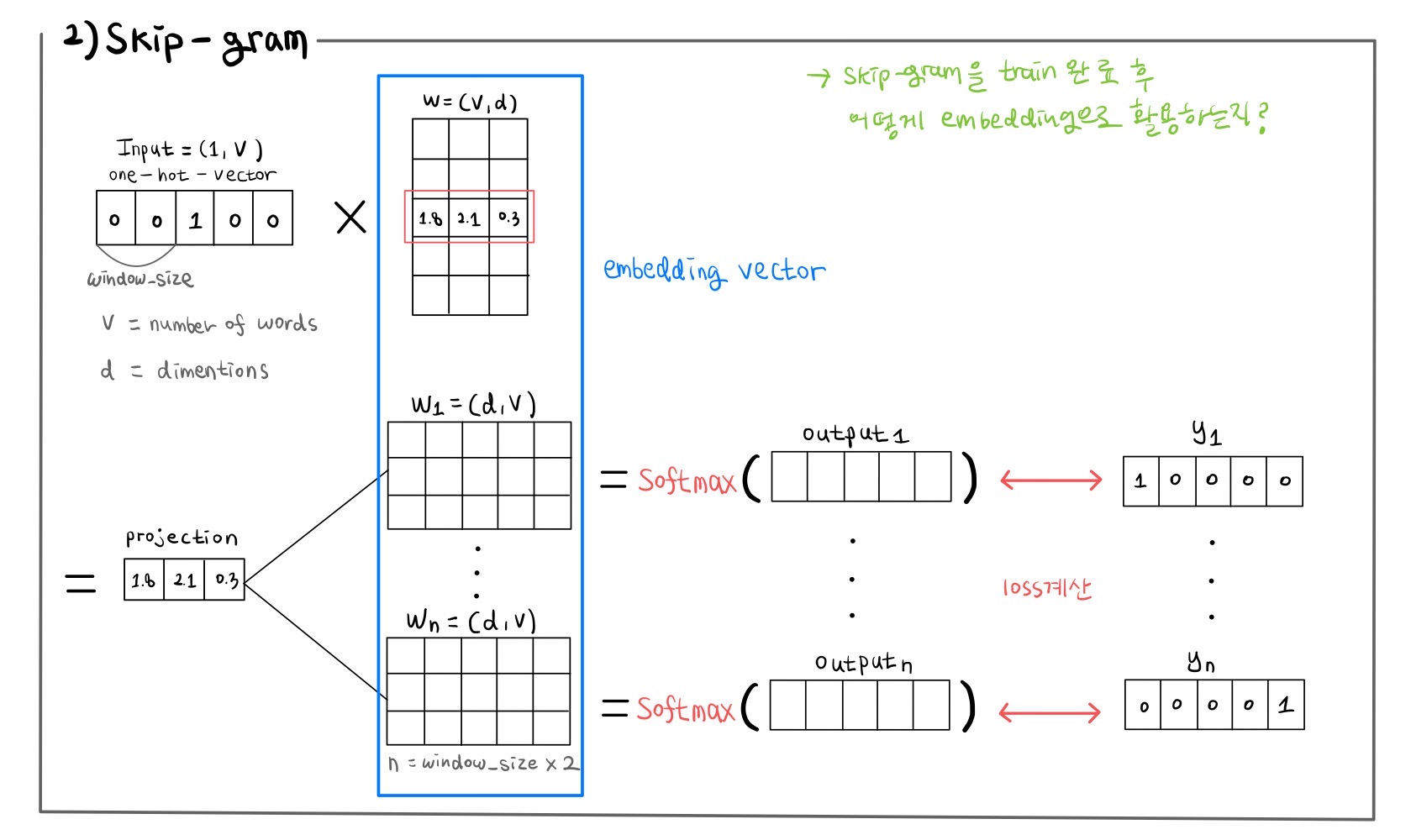
[NLP] Word2Vec : Skip-gram, SGNS(Skip-gram with Negative Sampling) Word2Vec의 학습방식을 공부하고 남기는 노트 자료입니다. 상세한 설명은 [WikiDocs]딥 러닝을 이용한 자연어 처리 입문 에서 보면 좋을 것 같습니다. 먼저 CBOW(Continuous Bag of Words)의 구조는 넣지 않았습니다. Skip-gram을 이해하면 쉽게 이해할 수 있는 구조입니다. 학습방식을 사전에 충분히 숙지한 뒤 나중에 참고용으로 보면 좋을 것 같습니다.(는 내 얘기) Study/NLP 2022.04.20
[NLP] Seq2Seq, Attention Algorithm Structure Seq2Seq, sequence to sequence seq2seq는 두 개의 RNN을 encoder와 decoder구조로 연결하여 사용하는 모델이다. 이러한 encoder-decoder 구조는 입력 문장과 출력 문장의 길이가 다를 경우 사용한다. 번역(Translation) 텍스트 요약(Text Summarization) 음성 인식(SST, Speech to Text) Seq2Seq의 구조를 요약하여 그려보았다. 처음 접한다면 이 구조만 보고 이해하기 어려울 것이다. Seq2Seq 프로세스를 숙지하여 본다면 요약본으로 보기 좋을 것 같다. Input word(Iw) / Target word(Tw) / Predict word(Pw)는 내가 이해하기 쉽게 명칭을 적어놓았다.. Attention Model .. Study/NLP 2022.04.10
[WikiDocs] 딥러닝 자연어 처리 입문 노트 정리, Part 1 해당 포스트는 [WikiDocs] 딥 러닝을 이용한 자연어 처리 입문 을 보고 공부하면서 이론 위주의 요약 및 정리한 내용을 담았습니다. - 자연어의 이해 - 전처리 방법 텍스트 전처리 Text preprocessing 자연어는 데이터를 사용하고자하는 용도에 맞게 토큰화 / 정제 / 정규화 하는 일을 하게 됨 자연어 처리에서 전처리나 정규화의 지향점은 언제나 갖고 있는 corpus로부터 복잡성을 줄이는 것 Tokenization : 토큰화 Word Tokenization : 단어 토큰화 주어진 문장에서 token 이라고 불리는 단위로 나누는 작업 token 단위는 상황에 따라 다르지만 보통 의미있는 단위로 토큰을 정함 1) 구두점이나 특수 문자를 단순 제외해선 안됨 : $45 / 22-03-31 2) 줄.. Study/NLP 2022.04.05